Blog
How Breach & Attack Simulation Tools Can Help You Prepare for Ransomware Attacks
Read More
After implementing the hAFL1 fuzzer along with Ophir Harpaz, I decided to take hypervisor fuzzing to the next step. Here it is: SafeBreach Labs presents hAFL2 – the first open-source hypervisor fuzzer which supports nested virtualization and is capable of fuzzing any hypervisor natively.
We recommend these sources to help you become familiar with fuzzing and virtualization:
This blog post describes the modifications and parts that were added to the kAFL project in order to enable hypervisor fuzzing.
The hAFL2 infrastructure contains the following components:
As kAFL uses the KVM Hypervisor with Intel PT, this blog only refers to the nested virtualization architecture of Intel processors and uses KVM terminology as well.
Nested virtualization is almost entirely implemented within KVM as Intel VMX only supports handling one logical unit of CPU at a time. Therefore KVM must be aware of each one of the nested VMs which are running within the nested hypervisor and almost fully manage each one as well.
This fact is great for us because it means that we have full control over any of the nested VMs on L2 from within KVM on L0 – it actually enables us to fully communicate with a nested VM by:
We’ll get back to these three points in the following sections.
In contrast to kAFL which only uses one level of virtualization (L1, a single VM which is being targeted), hAFL2 uses two levels of virtualization:
When it comes to Hyper-V, things might be a little bit different.
The large number of prior bugs indicated that there is a sizable attack surface within the Virtualization Service Providers (VSP) of Hyper-V. These VSPs are located within the root partition VM, and not within the Hyper-V.
The L2 layer consists of two VMs (a.k.a Hyper-V partitions):
Pay attention that both our guest VM and our target are located within the L2 layer. (In the previous scenario, our target – the hypervisor itself – was located within the L1 layer.)
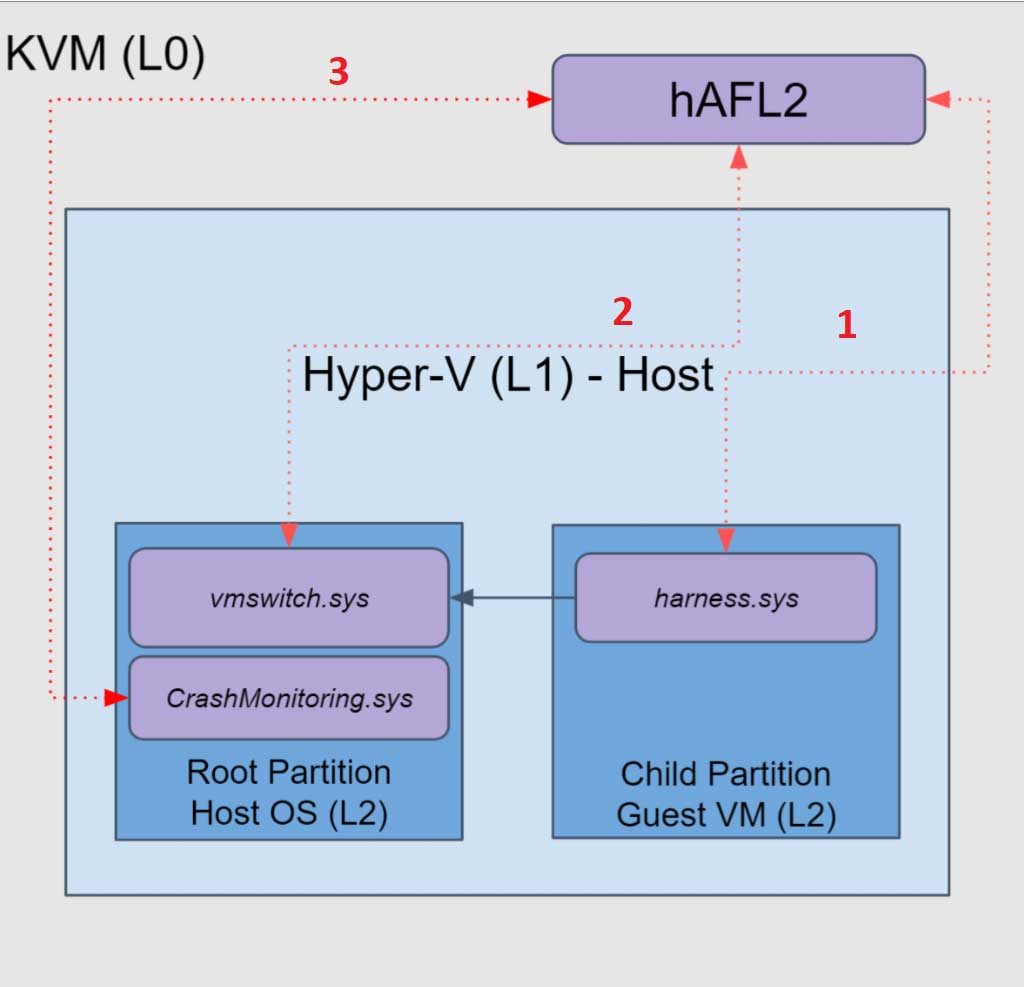
In order to fuzz a VSP, we will need to do the following (each bullet is marked with a number within the above diagram):
Now that we understand exactly what the basic blocks of hypervisor fuzzing are, it’s time to describe how we implemented each part of hAFL2:
EXIT_REASON_TOPA_FULL exit reasonkAFL leverages Intel PT in order to retrieve code coverage. Enabling Intel PT is possible by writing specific values to an MSR called IA32_RTIT_CTL.
In order to obtain code coverage only from the root partition VM (instead of retrieving it from the Hyper-V itself or the child partition VM), we need to enable Intel PT only for the root partition VM. To do so, the IA32RTITCTL MSR should be enabled for a specific VM.
KVM is perfectly aware of which VM is being handled at any time (nested or not.) In order to enable code coverage of a nested VM, modification to the VM-Entry and VM-Exit handlers of KVM is required. In addition, enabling ordisabling the IA32_RTIT_CTL MSR is only required when we are handling the root partition VM.
The following code modification was added within the vmx_vcpu_run function in arch/x86/kvm/vmx/vmx.c for VM-Entry (enabling Intel PT):
As mentioned before, this modification works for Hyper-V’s root partition, but you can easily modify it to support any other hypervisors, by using the following condition instead of is_root_partition:
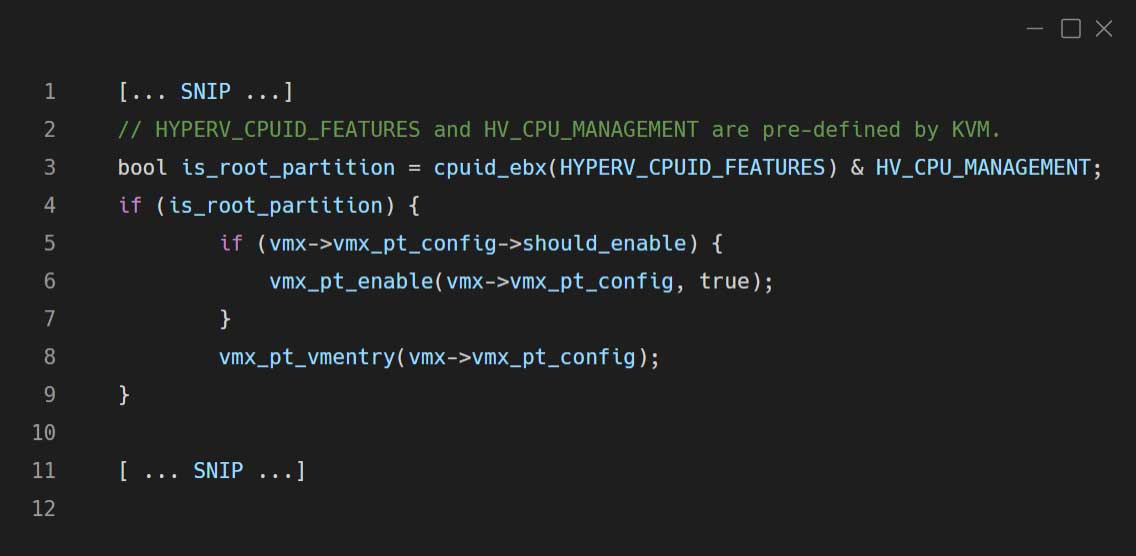

Just replace the last_vpid with the virtual processor id of your target VM. (It should be 0 for the target hypervisor itself, at least for Hyper-V.)
The same modification (disabling Intel PT) was also implemented for VM-Exit within the vmx_handle_exit_irqoff function in arch/x86/kvm/vmx/vmx.c:
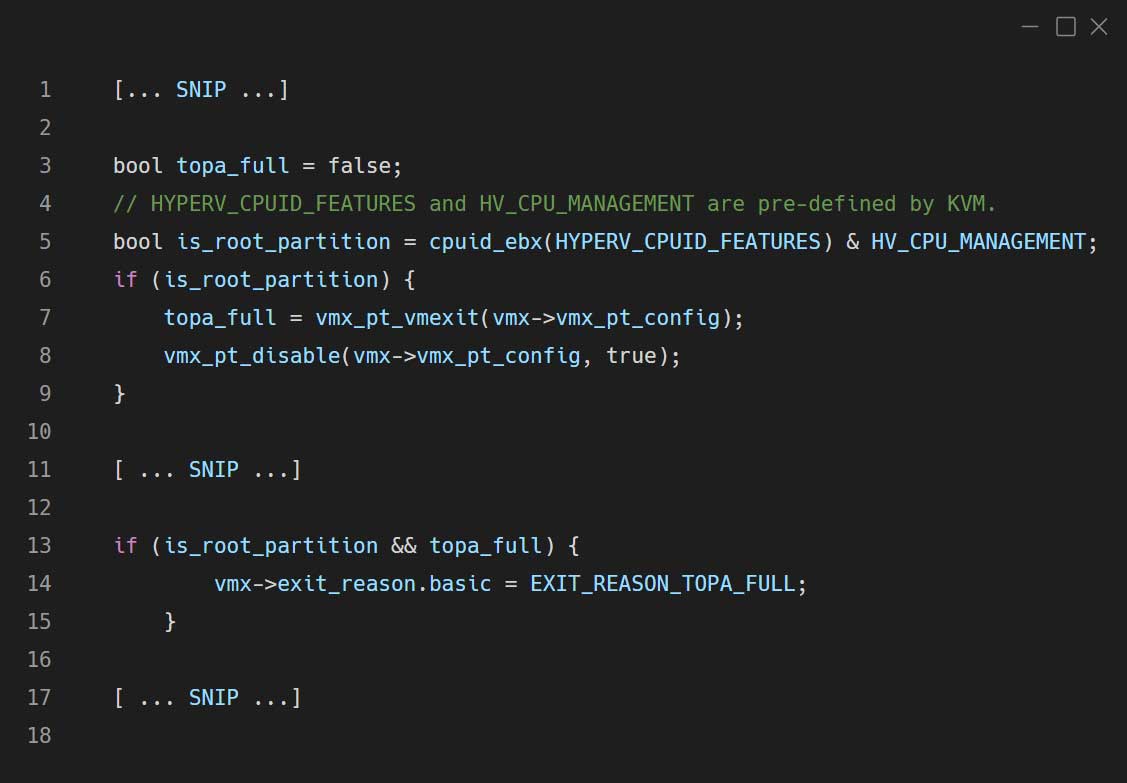
EXIT_REASON_TOPA_FULL exit reasonkAFL specifies the EXIT_REASON_TOPA_FULL exit reason for a certain VM (in our scenario, it is the root partition VM), whenever the ToPA buffers of Intel PT are full.
KVM actually handles the exit reason of a nested VM before it is reflected to the L1 hypervisor. The target hypervisor doesn’t know this exit reason as it’s implemented by kAFL modifications. Therefore we have to tell KVM not to transfer this exit reason to L1. Eventually, it will be handled within KVM.
This modification was added within the nested_vmx_reflect_vmexit function in arch/x86/kvm/vmx/nested.c: .
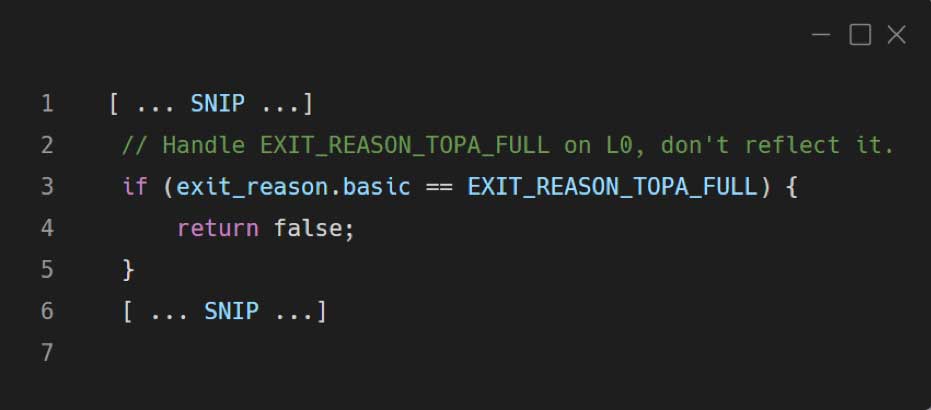
kAFL adds a hypercall which enables the guest VM to communicate with KVM directly (for example, synchronizing between the harness and the fuzzer, indicating a crash, etc.). A hypercall causes a VM-Exit with the EXIT_REASON_VMCALL exit reason.We need to make sure that this exit reason is handled within KVM and isn’t transferred to the L1 hypervisor. In order to do so, we modify the following code (the nested_vmx_reflect_vmexit function in arch/x86/kvm/vmx/nested.c🙂
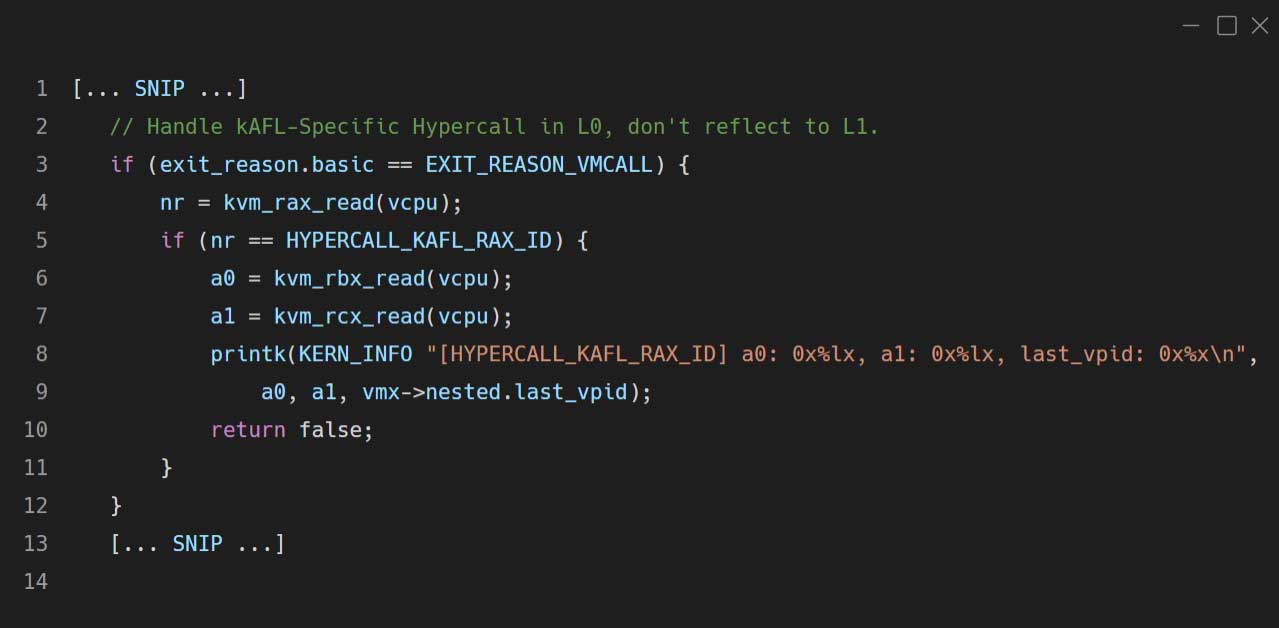
After the modification, KVM forwards the kAFL-originated hypercalls to QEMU-PT which contains the hypercall handling part of kAFL. (The implementation can be found within qemu-6.0.0/accel/kvm/kvm-all.c.)
kAFL uses the QEMU API in order to read from or write to the guest memory (or example, f reading the target’s memory and disassembling it for code coverage, writing the fuzzing payloads to the guest’s buffer, etc.).
When it comes to nested virtualization, QEMU tries to convert the GVA of L2 by using the memory mapping of L1. (It won’t work because we need to use the L2 memory mapping).
In contrast to QEMU, KVM is actually fully aware of the nested VM memory mapping, so when it tries to convert a GVA to a GPA it actually uses the vcpu->arch.walk_mmu struct which is fully aware of any VM memory mapping including nested ones (by leveraging the Intel EPT mechanism):
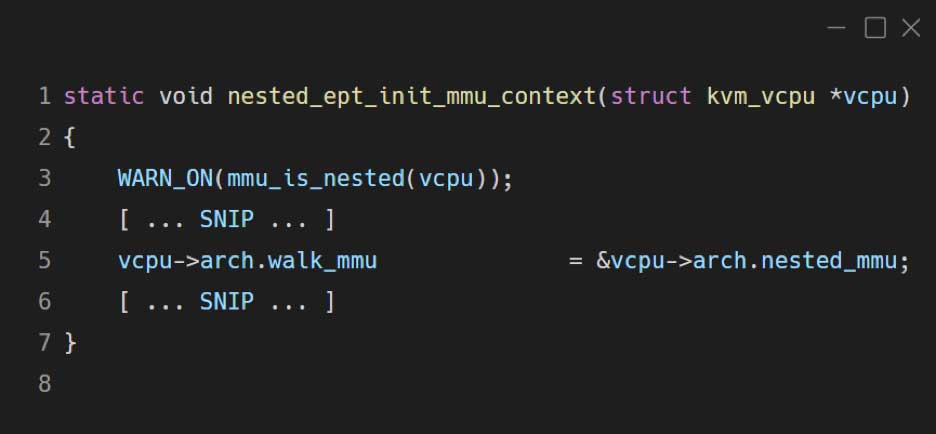
The first nested VM memory R/W originated in the disassembler component of QEMU-PT, which disassembles the target’s code as part of its code coverage retrieval. It maps a GVA directly to QEMU in order to read the target’s memory in an efficient manner.
KVM implements an IOCTL named KVM_TRANSLATE which translates GVA to GPA. This works with nested GVAs, of course. All I had to do was modify QEMU-PT so it will translate GVAs by leveraging KVM, instead of doing it on its own (The example is from the analyse_assembly function in qemu-6.0.0/pt/disassembler.c:).

The second nested VM memory R/W originated in the QEMU hypercalls handling implementation, for example, writing the fuzzing payloads to the harness buffers, reading the crash details from the root partition VM, etc.
In order to solve this part, I implemented two KVM IOCTLs: KVM_VMX_PT_WRITE_TO_GUEST and KVM_VMX_PT_READ_FROM_GUEST which provided QEMO with read/write access to the memory from a nested VM by using KVM instead of trying to perform it on its own.
After implementing both the KVM and QEMU parts, the relevant read_virtual_memor / write_virtual_memory calls in QEMU were replaced with read_virtual_memory_via_kvm / write_virtual_memory_via_kvm.
The implementation of the QEMU-side functions can be found within qemu-6.0.0/pt/memory_access.c. The implementation of the KVM-side functionality can be found within the kvm_arch_vcpu_ioctl function in /arch/x86/kvm/x86.c.
The harness and crash monitoring parts have now been completed.
The original kAFL project supports QEMU 5.0.0.
When I tried to take the final fuzzing snapshot of my target VM (which contains Hyper-V, the root partition and a child partition), I noticed that the guest was frozen when the snapshot was resumed. I’m not sure what exactly the problem was, but porting the fuzzer to QEMU-6.0.0 solved the problem.
You may look at the patches in order to understand exactly what modifications were required.
hAFL2 is the first open-source hypervisor fuzzer which was publicly released.
The hAFL2 modifications that were added to kAFL within this project provide all of the basic building blocks which are required in order to start the fuzzing process for a hypervisor target.
We encourage you to use this project in order to learn about hypervisor and virtualization internals, gain fuzzing experience and find new bugs with it.
The hAFL2 repository is stored on GitHub: https://github.com/SafeBreach-Labs/hAFL2